DeepSeek R1:功能、o1 比较、提炼模型等
DeepSeek 刚刚宣布推出DeepSeek-R1 ,这是其推理模型研究的下一步。这是其早期DeepSeek-R1-Lite-Preview的升级版,表明他们认真考虑与OpenAI 的 o1竞争。
OpenAI 计划于今年晚些时候发布 o3,显然推理模型的竞争正在加剧。尽管 DeepSeek 在某些领域可能略显落后,但其开源性质和明显较低的价格使其成为 AI 社区的一个引人注目的选择。
在这篇博客中,我将分解 DeepSeek-R1 的主要功能、开发过程、提炼模型、如何访问它、定价以及它与 OpenAI 模型的比较。
 我最初在 DeepSeek-R1 发布当天写了这篇文章,但现在我对其进行了更新,增加了一个新部分,介绍其后果——它如何影响股票市场、人工智能经济学(包括杰文斯悖论和人工智能模型的商品化),以及 OpenAI 对 DeepSeek 提炼其模型的指责。
我最初在 DeepSeek-R1 发布当天写了这篇文章,但现在我对其进行了更新,增加了一个新部分,介绍其后果——它如何影响股票市场、人工智能经济学(包括杰文斯悖论和人工智能模型的商品化),以及 OpenAI 对 DeepSeek 提炼其模型的指责。
什么是 DeepSeek-R1?
DeepSeek-R1 是由中国人工智能公司 DeepSeek 开发的开源推理模型,用于解决需要逻辑推理、数学问题解决和实时决策的任务。
DeepSeek-R1 和 OpenAI 的 o1 等推理模型与传统语言模型的不同之处在于,它们能够展示如何得出结论。
借助 DeepSeek-R1,您可以遵循其逻辑,从而更容易理解,并在必要时质疑其输出。此功能使推理模型在需要解释结果的领域(如研究或复杂决策)具有优势。
DeepSeek-R1 的开源特性使其特别具有竞争力和吸引力。与专有模型不同,其开源特性允许开发人员和研究人员在某些技术限制(例如资源要求)内探索、修改和部署它。
DeepSeek-R1 是如何开发的?
在本节中,我将引导您了解 DeepSeek-R1 的开发过程,从它的前身 DeepSeek-R1-Zero 开始。
DeepSeek-R1-Zero
DeepSeek-R1 始于 R1-Zero,这是一个完全通过强化学习训练的模型。虽然这种方法使其能够开发出强大的推理能力,但它也存在重大缺陷。输出通常难以阅读,并且模型有时会在其响应中混合语言。这些限制使得 R1-Zero 在实际应用中不太实用。
纯强化学习的挑战
单纯依赖强化学习会产生逻辑合理但结构不良的输出。在没有监督数据指导的情况下,该模型很难有效地传达其推理。这对于需要结果清晰度和准确性的用户来说是一个障碍。
DeepSeek-R1 的改进
为了解决这些问题,DeepSeek 在 R1 的开发中做出了改变,将强化学习与监督微调相结合。这种混合方法结合了精选数据集,提高了模型的可读性和连贯性。语言混合和碎片化推理等问题显著减少,使模型更适合实际使用。
如果你想了解有关 DeepSeek-R1 开发的更多信息,我建议阅读发布论文。
DeepSeek-R1 的精简模型
人工智能中的提炼是从较大的模型中创建较小、更高效的模型的过程,在保留大部分推理能力的同时减少计算需求。DeepSeek 应用此技术从 R1 中使用 Qwen 和 Llama 架构创建了一套提炼模型。
基于 Qwen 的提炼模型
DeepSeek 基于 Qwen 的提炼模型注重效率和可扩展性,在性能和计算要求之间实现平衡。
DeepSeek-R1-Distill-Qwen-1.5B
这是最小的精简模型,在 MATH-500 上达到 83.9%。MATH-500 测试使用逻辑推理和多步骤解决方案解决高中数学问题的能力。这一结果表明,尽管模型体积小,但能够很好地处理基本的数学任务。
然而,在用于评估编码能力的基准 LiveCodeBench (16.9%) 上,它的性能大幅下降,凸显出其在编程任务中的能力有限。
DeepSeek-R1-Distill-Qwen-7B
Qwen-7B 在 MATH-500 测试中表现出色,得分为 92.8%,表明其数学推理能力很强。它在评估事实问题回答能力的 GPQA Diamond 测试中也表现良好(49.1%),表明其在数学和事实推理之间取得了良好的平衡。
然而,它在 LiveCodeBench(37.6%)和 CodeForces(1189 评分)上的表现表明它不太适合复杂的编码任务。
DeepSeek-R1-Distill-Qwen-14B
该模型在 MATH-500 测试中表现优异(93.9%),反映出其处理复杂数学问题的能力。其在 GPQA Diamond 测试中取得的 59.1% 的成绩也表明其具有事实推理能力。
它在 LiveCodeBench(53.1%)和 CodeForces(1481 评分)上的表现显示出在编码和编程特定的推理任务方面还有上升空间。
DeepSeek-R1-Distill-Qwen-32B
最大的基于 Qwen 的模型在 AIME 2024(72.6%)中取得了同类中的最高分,该模型评估了高级多步数学推理。它在 MATH-500(94.3%)和 GPQA Diamond(62.1%)中也表现出色,展示了其在数学和事实推理方面的实力。
它在 LiveCodeBench(57.2%)和 CodeForces(1691 评分)上的结果表明,与专门用于编码的模型相比,它功能多样,但尚未针对编程任务进行优化。
基于骆驼的蒸馏模型
DeepSeek 基于 Llama 的提炼模型优先考虑高性能和高级推理能力,尤其擅长需要数学和事实精度的任务。
DeepSeek-R1-Distill-Llama-8B
Llama-8B 在 MATH-500 上表现良好(89.1%),在 GPQA Diamond 上表现一般(49.0%),表明其能够处理数学和事实推理。然而,它在 LiveCodeBench(39.6%)和 CodeForces(1205 分)等编码基准测试中的得分较低,这凸显了与基于 Qwen 的模型相比,其在编程相关任务方面的局限性。
DeepSeek-R1-Distill-Llama-70B
最大的提炼模型 Llama-70B 在 MATH-500 上表现顶级(94.5%),是所有提炼模型中最好的,并在 AIME 2024 上取得了 86.7% 的高分,成为高级数学推理的绝佳选择。
它在 LiveCodeBench(57.5%)和 CodeForces(1633 分)上的表现也非常出色,这表明它在编码任务上比大多数其他模型更胜任。在这个领域,它与 OpenAI 的 o1-mini 或 GPT-4o 不相上下。
如何访问 DeepSeek-R1
您可以通过两种主要方式访问 DeepSeek-R1:基于 Web 的 DeepSeek 聊天平台和 DeepSeek API,让您可以选择最适合您需求的选项。
网页访问:DeepSeek 聊天平台
DeepSeek 聊天平台提供了一种与 DeepSeek-R1 交互的直接方式。要访问它,您可以直接转到聊天页面,也可以单击主页上的“立即开始” 。
注册后,您可以选择“深度思考”模式来体验Deepseek-R1的逐步推理能力。
API 访问:DeepSeek 的 API
为了将 DeepSeek-R1 集成到您的应用程序中,DeepSeek API 提供了编程访问。
首先,您需要通过在DeepSeek 平台上注册来获取 API 密钥。
该 API 与 OpenAI 的格式兼容,如果您熟悉 OpenAI 的工具,则可以轻松集成。您可以在DeepSeek 的 API 文档中找到更多说明。
DeepSeek-R1 定价
自 2025 年 1 月 21 日起,聊天平台可免费使用,但在“深度思考”模式下,每日消息上限为 50 条。此限制使其非常适合轻度使用或探索。
该 API 提供两种模型deepseek-chat(DeepSeek-V3)和deepseek-reasoner(DeepSeek-R1),定价结构如下(每 100 万个代币):
模型
上下文长度
MAX COT 代币
最大输出代币
100 万个代币
投入价格
(缓存命中)
100 万个代币
投入价格
(缓存未命中)
100 万个代币
产出价格
| deepseek 聊天 | 64千 | – | 8K | 0.07 美元
0.014美元 |
0.27 美元
0.14美元 |
1.10 美元
0.28 美元 |
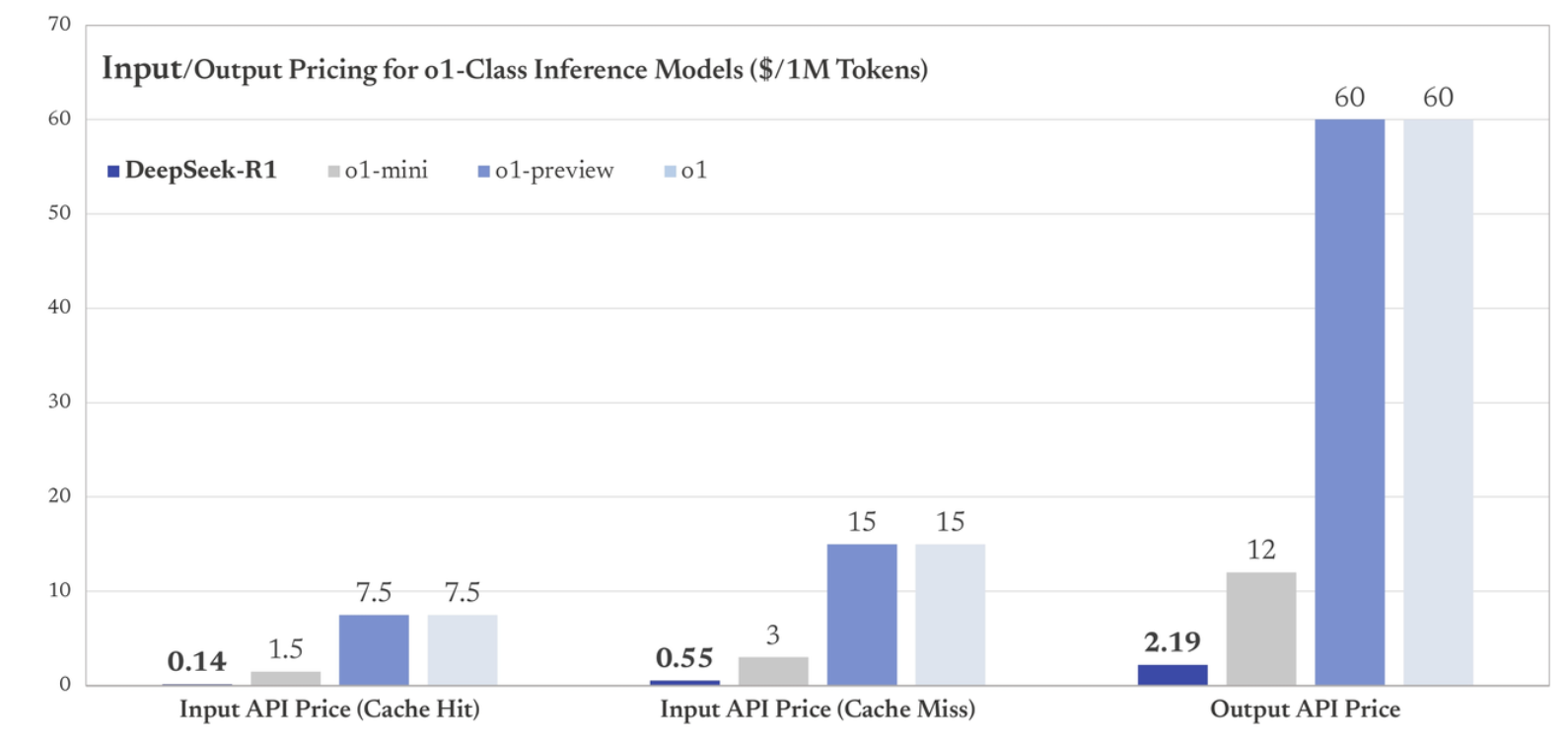
| deepseek-reasoner | 64千 | 3.2万 | 8K | 0.14美元 | 0.55 美元 | 2.19 美元 |
为了确保您拥有最新的定价信息并了解如何计算 CoT(思想链)推理的成本,请访问DeepSeek 的定价页面。
DeepSeek-R1 与 OpenAI O1:基准性能
DeepSeek-R1 在多个基准测试中与 OpenAI o1 直接竞争,并且经常匹敌或超越 OpenAI 的 o1。
数学基准:AIME 2024 和 MATH-500
在数学基准测试中,DeepSeek-R1 表现出色。在评估高级多步数学推理的 AIME 2024 上,DeepSeek-R1 的得分为 79.8%,略高于 OpenAI o1-1217 的 79.2%。
在 MATH-500 上,DeepSeek-R1 以惊人的 97.3% 领先,略高于 OpenAI o1-1217 的 96.4%。该基准测试针对需要详细推理的各种高中数学问题测试模型。
编码基准:Codeforces 和 SWE-bench Verified
Codeforces 基准测试评估模型的编码和算法推理能力,以与人类参与者的百分位排名表示。OpenAI o1-1217 以 96.6% 领先,而 DeepSeek-R1 则以非常有竞争力的 96.3% 领先,两者之间只有微小的差距。
SWE-bench Verified 基准测试评估软件工程任务中的推理能力。DeepSeek-R1 表现强劲,得分为 49.2%,略高于 OpenAI o1-1217 的 48.9%。这一结果使 DeepSeek-R1 成为软件验证等专业推理任务中的有力竞争者。
常识基准:GPQA Diamond 和 MMLU
对于事实推理,GPQA Diamond 衡量回答通用知识问题的能力。DeepSeek-R1 得分为 71.5%,落后于 OpenAI o1-1217,后者得分为 75.7%。这一结果凸显了 OpenAI o1-1217 在事实推理任务中的微弱优势。
在 MMLU(一项涵盖多个学科并评估多任务语言理解的基准测试)上,OpenAI o1-1217 略胜 DeepSeek-R1,得分为 91.8%,而 DeepSeek-R1 的得分为 90.8%。
DeepSeek 的后果
DeepSeek-R1 的发布产生了深远的影响,影响了股票市场、重塑了人工智能经济,并引发了模型开发实践的争议。
对股市的影响
DeepSeek 推出的 R1 模型可以提供先进的 AI 功能,但成本仅为竞争对手的一小部分,这导致美国主要科技公司的股价大幅下跌。
例如,Nvidia 的股价下跌了近 18%,相当于市值损失了约 6000 亿美元。投资者担心 DeepSeek 高效的 AI 模型可能会减少对传统上由 Nvidia 等公司提供的高性能硬件的需求,这导致了股价下跌。
杰文斯悖论与人工智能模型的商品化
像 DeepSeek-R1 这样的开放权重模型正在降低成本,并迫使 AI 公司重新考虑其定价策略。这在鲜明的定价对比中显而易见:
- OpenAI 的 o1 每百万输出代币成本为 60 美元
- DeepSeek-R1 每百万输出代币成本为 2.19 美元
一些行业领袖指出了杰文斯悖论——随着效率的提高,总体消费会上升而不是下降。微软首席执行官萨蒂亚·纳德拉暗示了这一点,他认为随着人工智能变得越来越便宜,需求将会激增。
不过,我喜欢《经济学人》的这种平衡观点,该观点认为,完全的杰文斯效应非常罕见,取决于价格是否是采用人工智能的主要障碍。鉴于“目前只有 5% 的美国公司使用人工智能,7% 的公司计划采用人工智能”,杰文斯效应可能很低。许多企业仍然认为人工智能集成很困难或没有必要。
OpenAI 指责 DeepSeek 存在蒸馏现象
除了颠覆性的影响外,DeepSeek 也陷入了争议的漩涡。OpenAI 指责 DeepSeek对其模型进行了提炼——本质上是从 OpenAI 的专有系统中提取知识,并在更紧凑、更高效的模型中复制其性能。
到目前为止,OpenAI 尚未提供直接证据证明这一说法,对许多人来说,这一指控更像是在人工智能格局不断变化的背景下安抚投资者的战略举措。
结论
DeepSeek-R1 是推理 AI 领域的强劲竞争对手,其表现可与 OpenAI 的 o1 相媲美。虽然 OpenAI 的 o1 在编码和事实推理方面可能略有优势,但我认为 DeepSeek-R1 的开源性质和经济高效的访问使其成为一个有吸引力的选择。
随着 OpenAI 准备发布 o3,我期待看到这场日益激烈的竞争将如何塑造推理模型的未来。目前,DeepSeek-R1 是一个引人注目的替代方案。
常见问题解答
DeepSeek-R1 如何处理多语言查询?
DeepSeek-R1 针对英语和中文进行了优化,但对于其他语言的查询,其性能可能会下降。某些输出可能会混合英文和中文,尤其是在处理推理任务时。未来的更新有望解决这一限制。
DeepSeek-R1 可以针对特定任务或行业进行微调吗?
是的,作为一个开源模型,DeepSeek-R1 可以针对特定任务进行微调,只要您拥有必要的计算资源和数据。这种灵活性对于需要特定领域应用的研究人员和组织来说尤其有吸引力。
DeepSeek-R1 的输出长度有限制吗?
是的,DeepSeek-R1 的输出 token 限制因访问方式而异。例如,API 的deepseek-reasoner模型支持的最大输出长度为 8,000 个 token,其中包括推理步骤(Chain-of-Thought)和最终答案。
在本地运行 DeepSeek-R1 需要什么样的硬件?
在本地运行 DeepSeek-R1 或其精简模型需要高性能 GPU 或 TPU,尤其是对于 DeepSeek-R1-Distill-Llama-70B 等较大的模型。对于资源有限的系统来说,较小的精简版本(例如 Qwen-1.5B)更为可行。
上下文缓存在 DeepSeek 的 API 中如何工作,以及它能节省多少?
上下文缓存会存储重复的输入标记以降低成本。例如,如果您在多轮对话中重复使用输入,系统会以低得多的价格从缓存中检索这些标记。此功能对于具有重复查询的工作流特别有用。
作者:亚历克斯·奥尔泰亚努 编辑:AIToolGrid
© Copyright notes
If there is no special statement, the copyright of all articles on this site belongs to AIToolGrid. Without permission, any individual, media, website, or organization may not reproduce, plagiarize, or otherwise copy and publish the content of this site. Otherwise, AIToolGrid reserves the right to pursue related legal responsibilities.
Related posts

No comments...