什么是 Google Gemini?您需要了解的有关 Google ChatGPT 竞争对手的一切
谷歌称该模型是他们迄今为止开发的最强大、用途最广泛的人工智能,其设计为多模式。这意味着 Gemini 可以理解各种数据类型,例如文本、音频、图像、视频和代码。
什么是 Google Gemini?
2023 年 12 月 6 日,Google DeepMind 宣布推出 Gemini 1.0。发布时,Google 称其为最先进的大型语言模型(LLM) 集,从而取代了同年 5 月推出的 Pathways 语言模型 (PaLM 2)。
Gemini 定义了一系列多模态 LLM,能够理解文本、图像、视频和音频。据说它还能够执行复杂的数学和物理任务,并能够用多种编程语言生成高质量的代码。
有趣的是:谷歌联合创始人谢尔盖·布林 (Sergey Brin) 被认为是双子座模型的贡献者之一。
直到最近,开发多模态模型的标准程序包括训练各个组件以适应各种模态,然后将它们拼凑在一起以模拟某些功能。此类模型偶尔会擅长执行某些任务,例如描述图像,但它们在更复杂的推理方面却存在困难。
Gemini 的设计初衷是实现原生多模态;因此,它从一开始就针对多种模态进行了预训练。为了进一步提高其功效,Google 使用额外的多模态数据对其进行了微调。
因此,谷歌和 Alphabet 首席执行官 Sundar Pichai 和谷歌 DeepMind 首席执行官兼联合创始人 Demis Hassabis 表示,Gemini 在从头开始理解和推理各种输入方面的能力明显优于现有的多模态模型。他们还表示,Gemini 的能力“在几乎所有领域都是最先进的”。
Google Gemini 主要功能
Gemini 模型的主要特点包括:
1. 理解文本、图像、音频等
多模态 AI 是一种越来越流行的新型 AI 范式,其中不同的数据类型与多种算法相结合以实现更高的性能。Gemini 利用了这种范式,这意味着它可以与各种数据类型很好地集成。您可以输入图像、音频、文本和其他数据类型,从而实现更自然的 AI 交互。
2.可靠性、可扩展性和效率
Gemini 利用了 Google 的 TPUv5 芯片,因此据称其性能比 GPT-4 强五倍。更快的处理速度使 Gemini 能够相对轻松地处理复杂任务并同时处理多个请求。
3. 复杂的推理
Gemini 是在庞大的文本和代码数据集上进行训练的。这确保模型可以访问最新的信息并为您的查询提供准确可靠的响应。据谷歌称,该模型在各种智力测试(例如 MMLU 基准)中的表现优于 OpenAI 的 GPT-4 和“专家级”人类。
4. 高级编码
Gemini 1.0 可以理解、解释和生成最广泛使用的编程语言(如 Python、Java、C++ 和 Go)的高质量代码——这使其成为全球领先的编码基础模型之一。
该模型还在多个编码基准测试中表现出色,包括HumanEval,这是评估编码任务性能的备受推崇的行业标准;它在谷歌的内部保留数据集上也表现良好,该数据集利用作者生成的代码而不是来自网络的信息。
5. 责任与安全
谷歌的AI 原则和政策中增加了新的保护措施,以应对 Gemini 的多模态能力。谷歌表示,“Gemini 拥有迄今为止所有谷歌 AI 模型中最全面的安全评估,包括偏见和毒性。”他们还表示,他们“对网络攻击、说服和自主性等潜在风险领域进行了新颖的研究,并应用了谷歌研究部门一流的对抗性测试技术,以帮助在 Gemini 部署之前识别关键的安全问题。”
双子座 (Gemini) 有哪些版本?
谷歌表示,Gemini 是LaMDA和 PaLM 2的继任者,是他们“迄今为止最灵活的模型——能够在从数据中心到移动设备的所有设备上高效运行”。他们还相信,Gemini 的先进功能将改善开发人员和商业客户利用 AI 进行构建和扩展的方式。
Gemini 的第一个版本毫无意外地被命名为 Gemini 1.0,并发布了三种不同尺寸:
- Gemini Nano — Gemini Nano 是处理需要高效 AI 处理而无需连接外部服务器的设备内任务的最高效模型。换句话说,它是为在智能手机上运行而设计的,特别是 Google Pixel 8。
- Gemini Pro — Gemini Pro 是跨各种任务扩展的最佳模型。它旨在为Google 最新的 AI 聊天机器人Bard提供支持;因此,它可以理解复杂的查询并快速做出响应。
- Gemini Ultra ——Gemini Ultra 是用于执行复杂任务的最大、功能最强的模型,在大型语言模型 (LLM) 研究和开发的 32 个常用基准中的 30 个中超过了当前最先进的结果。
如何访问 Gemini?
自 2023 年 12 月 13 日起,开发人员和企业客户可以通过 Google AI Studio 或 Google Cloud Vertex AI 中的 Gemini API 访问 Gemini Pro。
注意:Google AI Studio 是一款免费的基于浏览器的 IDE,开发人员可以使用它来制作生成模型原型,并使用 API 密钥轻松启动应用程序。另一方面,Google Cloud Vertex 是一个完全托管的 AI 平台,提供构建和使用生成 AI所需的所有工具。据 Google 称,“Vertex AI 允许对 Gemini 进行定制,具有完全的数据控制,并受益于 Google Cloud 的其他功能,以实现企业安全、隐私和数据治理与合规性。”
通过Android 14 的新系统功能AICore,从 Pixel 8 Pro 设备开始,Android 开发者可以使用 Gemini Nano(最高效的设备端任务模型)进行构建。
探索 Gemini 基准
在发布之前,Gemini 模型经过了广泛的测试,以评估其在广泛任务中的表现。谷歌表示,其 Gemini Ultra 模型在 32 个常用大型语言模型 (LLM) 研发学术基准中的 30 个上超越了现有的最先进结果。请注意,这些任务范围从自然图像、音频和视频理解到数学推理。
在 Gemini 的介绍性博客文章中,谷歌声称 Gemini Ultra 是有史以来第一个在大规模多任务语言理解(MMLU) 方面超越人类专家的模型,得分为 90.0%。请注意,MMLU 包含 57 个不同的学科,包括数学、物理、历史、法律、医学和伦理学,以评估一个人解决问题的能力和对世界的一般理解。
新的 MMLU 基准测试方法使 Gemini 能够取得重大进步,而不是仅仅利用第一印象,利用其推理能力在回答具有挑战性的问题之前进行更彻底的思考。
Gemini 在文本任务上的表现如下:
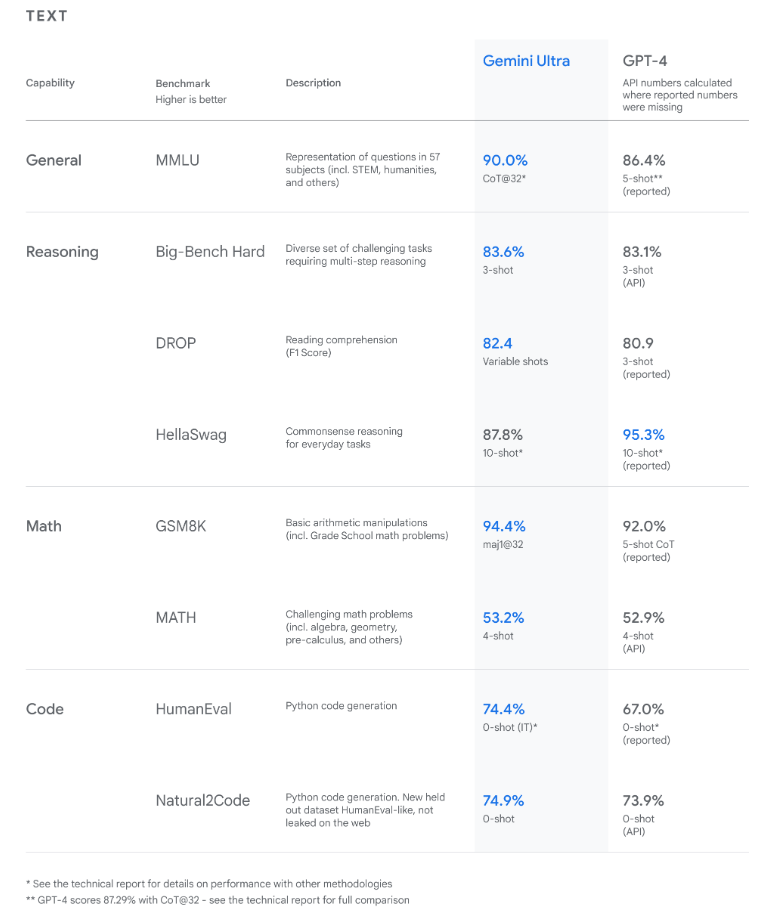
研究结果表明,Gemini 在文本和编码等一系列基准测试中的表现均超越了最先进的水平。[来源]
Gemini Ultra 模型还在新的大规模多学科多模态理解 (MMMU)基准中取得了 59.4% 的成绩,位居榜首。该评估包括跨多个领域的多模态任务,这些任务需要深思熟虑的推理。
谷歌表示:“通过我们测试的图像基准测试,Gemini Ultra 的表现优于之前最先进的模型,无需借助光学字符识别 (OCR) 系统(从图像中提取文本进行进一步处理)。”
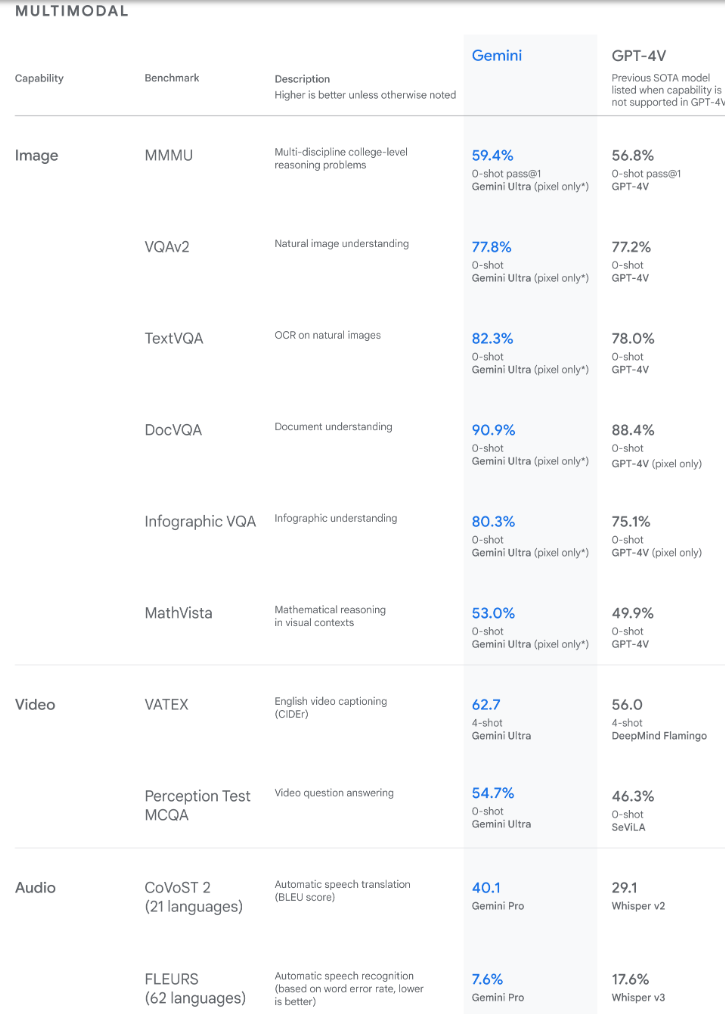
研究结果表明,Gemini 在一系列多模式基准测试中也超越了最先进的性能。[来源]
Gemini 设定的基准证明了该模型固有的多模态性,并显示了其进行更复杂推理的能力的早期证据。
Gemini 与 GPT-4
接下来通常出现的一个显而易见的问题是:“ Gemini 与GPT-4相比如何?”
两种模型具有相似的功能集,可以与文本、图像、视频、音频和代码数据进行交互和解释,从而使用户能够将它们应用于各种任务。
这两种工具的用户都可以选择进行事实核查,但它们提供此功能的方式不同。OpenAI 的 GPT-4 为其提出的主张提供了来源链接,而 Gemini 则允许用户通过单击按钮执行 Google 搜索来确认响应。
也可以通过额外的扩展来增强这两种模型,尽管在撰写本文时,谷歌的 Gemini 模型受到很大限制。
例如,Gemini 可以使用 Google 工具,例如航班、地图、YouTube 及其一系列 Workspace 应用程序。相比之下,OpenAI 的 GPT-4 提供的插件和扩展要多得多,其中大多数是由第三方创建的。GPT-4 还可以即时创建图像;Gemini 的设计初衷是能够实现这种功能,但在撰写本文时,它还不能实现。
另一方面,Gemini 的响应时间比 GPT-4 更快,后者可能会因为平台上的用户数量庞大而偶尔变慢或完全中断。
Gemini 的使用案例
Google 的 Gemini 模型可以跨多种模式执行各种任务,例如文本、音频、图像和视频理解。
由于 Gemini 的多模式特性,因此也可以结合不同的模式来理解和生成输出。
Gemini 的使用案例包括:
文本摘要
Gemini 模型可以从各种数据类型中总结内容。根据一篇题为《GEMINI:控制抽象文本摘要中的句子级摘要风格》的研究论文,Gemini 模型“集成了重写和生成器,分别模仿句子重写和摘要技术。”
也就是说,Gemini 会自适应地选择是否重写特定文档句子或完全从头开始生成摘要句子。实验结果表明,Gemini 使用的方法在三个基准数据集上的表现优于纯抽象和重写基线,在 WikiHow 上取得了最佳结果。
文本生成
Gemini 可以根据用户提示生成基于文本的输入 – 此文本也可以由问答式聊天机器人界面驱动。因此,Gemini 可以部署来处理客户查询并以自然而引人入胜的方式提供帮助,这可以释放人工代理的职责,使其能够更专注于复杂的任务并提高客户满意度。
它还可用于创意写作,例如合著小说、以各种风格创作诗歌或为电影和戏剧创作剧本。这可以大大提高创意作家的生产力,并减轻因写作障碍而产生的紧张感。
文本翻译和音频处理
凭借广泛的多语言能力,Gemini 模型可以理解和翻译 100 多种不同的语言。据 Google 称,Gemini 在“一系列多模式基准”上超越了 Chat GPT-4V 的领先性能,例如自动语音识别 (ASR)和自动语音翻译。
图像和视频处理
Gemini 能够理解和解读图像,因此非常适合用于图像字幕和视觉问答用例。该模型还可以解析复杂的视觉效果,包括图表、图形和图表,而无需外部 OCR 工具。
代码分析与生成
开发人员可以使用 Gemini 解决复杂的编码任务并调试代码。该模型能够理解、解释和生成最常用的编程语言,例如 Python、Java、C++ 和 Go。
结论
谷歌的新多模态大型语言模型 (LLM) Gemini 是 LaMDA 和 PaLM 2 的继任者。他们将其描述为最先进的 LLM 集,能够理解文本、图像、视频、音频以及数学和物理等复杂任务。Gemini 还能够用许多最流行的编程语言生成高质量代码。
该模型在各种任务中都达到了最先进的水平,谷歌的许多员工认为,它代表了人工智能在帮助改善我们日常生活方面的重大飞跃。
在您离开之前,请不要忘记订阅我们的YouTube 频道。
© Copyright notes
If there is no special statement, the copyright of all articles on this site belongs to AIToolGrid. Without permission, any individual, media, website, or organization may not reproduce, plagiarize, or otherwise copy and publish the content of this site. Otherwise, AIToolGrid reserves the right to pursue related legal responsibilities.
Related posts


No comments...