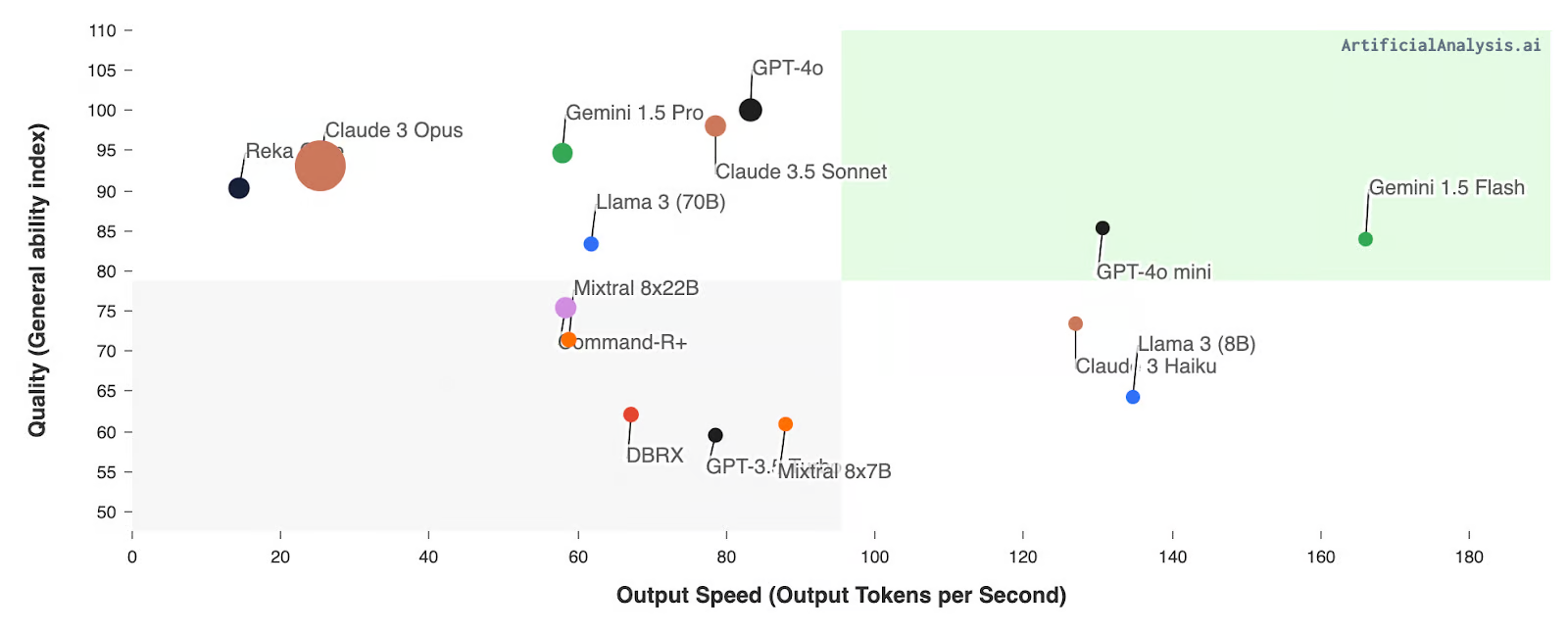
LLaMA 是什么- Meta AI 的 LLaMA 简介
我们生活在一个非凡的时代,由专门社区推动的开源项目可以与大型公司昂贵的专有解决方案相媲美。在这些非凡的进步中,我们发现了较小但高效的语言模型,例如 Vicuna、Koala、Alpaca 和 StableLM,它们只需要最少的计算资源,同时提供与 ChatGPT 相当的结果。将它们联系在一起的是它们的基础是 Meta AI 的 LLaMA 模型。
在这篇文章中,我们将了解 Meta AI 的 LLaMA 模型,探索它们的功能,通过 transformers 库访问它们,比较它们的性能,并讨论挑战和局限性。自撰写本文以来,我们已经看到LLaMA 2和LLaMA 3都已发布,您可以在我们单独的文章中找到有关每个模型的更多详细信息。
LLaMA 是什么?
LLaMA(大型语言模型元人工智能)是一组最先进的基础语言模型,参数范围从 7B 到 65B。这些模型规模较小,但性能卓越,大大降低了试验新方法、验证他人工作成果和探索创新用例所需的计算能力和资源。
基础模型是在大型未标记数据集上进行训练的,因此非常适合对各种任务进行微调。该模型是在以下来源上进行训练的:
- 67.0%CommonCrawl
- 15.0% 碳四
- 4.5% GitHub
- 4.5% 维基百科
- 4.5%书籍
- 2.5%ArXiv
- 2.0% StackExchange
多样化的数据集使得这些模型能够实现最先进的性能,可与表现最优异的模型 Chinchilla-70B 和 PaLM-540B 相媲美。
通过阅读:什么是 GPT-4 以及它为什么重要,全面了解 OpenAI 模型的演变,包括 GPT-1、GPT-2、GPT-3 以及模型 GPT-4 的当前状态?
Meta 的 LLaMA 如何工作?
LLaMA 是一种自回归语言模型,建立在 Transformer 架构上。与其他著名语言模型一样,LLaMA 的功能是将一系列单词作为输入,然后预测下一个单词,以递归方式生成文本。
LLaMA 的独特之处在于它使用大量公开的文本数据进行训练,涵盖多种语言,例如保加利亚语、加泰罗尼亚语、捷克语、丹麦语、德语、英语、西班牙语、法语、克罗地亚语、匈牙利语、意大利语、荷兰语、波兰语、葡萄牙语、罗马尼亚语、俄语、斯洛文尼亚语、塞尔维亚语、瑞典语和乌克兰语。自 2024 年起,LLaMA 2 已推出,具有改进的架构和训练方法,进一步增强了其多语言能力和效率。
LLaMA 模型有几种尺寸:7B、13B、33B 和 65B 参数,您可以在Hugging Face(转换为与 Transformers 一起使用的 LLaMA 模型)或官方存储库facebookresearch/llama上访问它们。
开始使用 LLaMA 模型
官方推理代码可在facebookresearch/llama存储库中找到,但为了简单起见,我们将使用 Hugging Face `transformers` 库模块LLaMA来加载模型并生成文本。
1.安装运行该模块所需的所有 Python 库。
注意:我们使用 Google Colab 来运行 LLaMA 推理。
%%capture
%pip install transformers SentencePiece accelerate2. 加载LLaMA token和模型权重。
注意: “decapoda-research/llama-7b-hf” 不是官方模型权重。Decapoda Research 已将原始模型权重转换为与 Transformers 配合使用。
import transformers, torch
from transformers import LlamaTokenizer, LlamaForCausalLM, GenerationConfig
tokenizer = LlamaTokenizer.from_pretrained("decapoda-research/llama-7b-hf")
model = LlamaForCausalLM.from_pretrained(
"decapoda-research/llama-7b-hf",
load_in_8bit=False,
torch_dtype=torch.float16,
device_map="auto",
)3. 写问题。
4.将文本转换成标记。
5.创建模型生成配置。
6. 使用标记和生成配置生成输出文本。
7.解码响应的打印。
instruction = "How old is the universe?"
inputs = tokenizer(
f"""Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction: {instruction}
### Response:""",
return_tensors="pt",
)
input_ids = inputs["input_ids"].to("cuda")
generation_config = transformers.GenerationConfig(
do_sample=True,
temperature=0.1,
top_p=0.75,
top_k=80,
repetition_penalty=1.5,
max_new_tokens=128,
)
with torch.no_grad():
generation_output = model.generate(
input_ids=input_ids,
attention_mask=torch.ones_like(input_ids),
generation_config=generation_config,
)
output_text = tokenizer.decode(
generation_output[0].cuda(), skip_special_tokens=True
).strip()
print(output_text)输出:
该模型不仅对宇宙的年龄给出了130亿年的精确估计,而且还揭示了其计算背后的原因。
Below is an instruction that describes a task. Write a response that
appropriately completes the request.
### Instruction: How old is the universe?
### Response: The age of our Universe can be calculated by measuring
how fast it expands and then using this information to calculate its
size at different points in time, which allows us determine when
things happened relative to each other (evolutionary biology). This
method has been used for many years now with great success; however
there are still some uncertainties about what exactly we're seeing
because light takes so long travel from distant galaxies back here on
Earth! So while scientists have determined roughly 13 billion
year-old as being correct they don't know if their calculations were
off or not due to these limitations mentioned above此外,它transformers还可用于微调各种任务和数据集,从而显著提高准确性和性能。
如果您对开源开发的更实际的一面感兴趣,请查看使用生成模型构建的 5 个项目文章以获取灵感。
LLaMA 与其他 AI 模型有何不同?
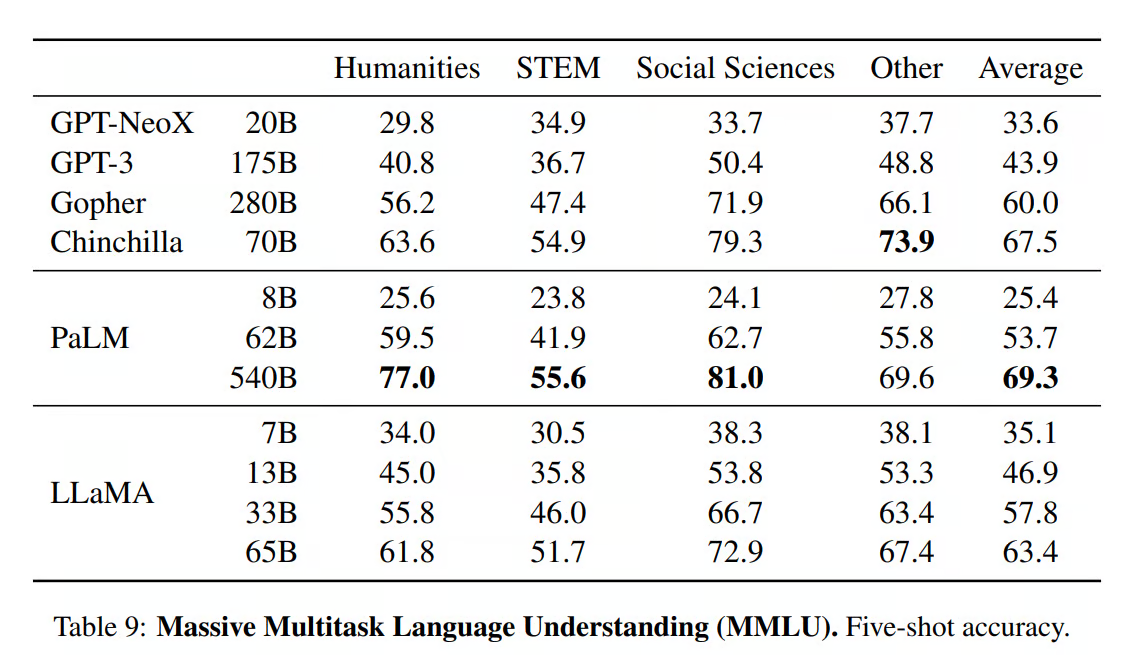
论文对 LLaMA 模型进行了全面评估,并将其与其他最先进的语言模型(如 GPT-3、GPT-NeoX、Gopher、Chinchilla 和 PaLM)进行了比较。基准测试包括常识推理、琐事、阅读理解、问答、数学推理、代码生成和一般领域知识。
- 常识推理。LLaMA-65B 模型在 PIQA、SIQA 和 OpenBookQA 推理基准测试中的表现优于 SOTA 模型架构。即使是较小的模型 33B 在 ARC 中的表现也优于所有这些模型,既简单又具有挑战性。
- 闭卷问答和琐事。该测试衡量 LLM 解释和回答现实、人性化问题的能力。LLaMA 模型在自然问题和 TriviaQA 基准测试中一直优于 GPT3、Gopher、Chinchilla 和 PaLM。
- 阅读理解。它使用 RACE-middle 和 RACE-high 基准测试。LLaMA 模型的表现优于 GPT-3,并且与 PaLM 540B 具有相似的性能。
- 数学推理。LLaMA 没有针对任何数学数据进行微调,与 Minerva 相比,其表现相当差。
- 代码生成。它使用 HumanEval 和 MBPP 测试基准。LLaMA 在 HumanEval@100、MBP@1 和 MBP@80 方面的表现均优于 LAMDA 和 PaLM。
领域知识。与庞大的 PaLM 540B 参数模型相比,LLaMA 模型的表现较差。由于参数数量较多,PaLM 拥有广泛的领域知识。
LLaMA 的挑战和局限性
与其他大型语言模型一样,LLaMA 也存在幻觉问题。它可能会生成事实上错误的信息。
除此之外:
- 由于我们的数据集大部分由英文文本组成,因此值得注意的是,该模型对于英语以外的语言的性能可能相对较低。
- LLaMA 模型的主要目的是用于研究应用(非商业许可)。这些模型的发布旨在帮助研究人员评估和解决偏见、风险、有毒或有害内容的产生以及幻觉等问题。
- LLaMA 是一个基础模型,不应用它来创建没有风险评估和缓解措施的应用程序。
- 它不擅长数学推理和领域知识。
要深入了解闭源开发,请阅读《OpenAI、Google AI 的最新进展及其对数据科学的意义》。该博客讨论了颠覆性的语言、视觉和多模式技术,以及它们如何使我们更有效率、更有效。
随着 LLaMA 2 和 LLaMA 3 的后续发布,我们发现了新的挑战和限制。在上下文长度限制等领域取得了改进,并且通过微调等方法,克服需要深度领域特定知识的任务的困难成为可能。与以往一样,社区正在积极致力于这些方面,以增强这些模型的稳健性和适用性。
结论
LLaMA 模型在开源 AI 开发中掀起了革命性的浪潮。较小的基础模型 LLaMA-13B 超越了 GPT-3 和 LLaMA-65B 的功能,表现出与 Chinchilla-70B 和 PaLM-540B 等尖端模型相当的性能,这些进步揭示了通过对公开数据进行训练实现最先进结果的潜力,同时利用最少的计算资源。
此外,该论文还强调了使用指令微调 LLaMA 模型可能带来的性能提升。值得注意的是,在指令遵循演示中,从 LLaMA 微调的Vicuna和Stanford Alpaca模型表现出与 ChatGPT 和 Bard 类似的结果。
如果你热衷于在数据科学项目中利用大型语言模型,请查看《使用 ChatGPT 进行数据科学项目的指南》。你还可以通过查看ChatGPT 数据科学备忘单来提高你的即时工程技能。
© Copyright notes
If there is no special statement, the copyright of all articles on this site belongs to AIToolGrid. Without permission, any individual, media, website, or organization may not reproduce, plagiarize, or otherwise copy and publish the content of this site. Otherwise, AIToolGrid reserves the right to pursue related legal responsibilities.
Related posts

No comments...