OpenAI o3-mini 发布
我们正在发布 OpenAI o3-mini,这是我们推理系列中最新、最具成本效益的模型,现已在 ChatGPT 和 API 中提供。这款功能强大且快速的模型于 2024 年 12 月进行了预览,它突破了小型模型所能实现的界限,提供了卓越的 STEM 功能(尤其擅长科学、数学和编码),同时保持了 OpenAI o1-mini 的低成本和低延迟。
OpenAI o3-mini 是我们的第一个小型推理模型,它支持开发人员高度要求的功能,包括函数调用(在新窗口中打开),结构化输出(在新窗口中打开)以及开发者消息(在新窗口中打开),使其可以立即投入生产。与 OpenAI o1-mini 和 OpenAI o1-preview 一样,o3-mini 将支持流媒体(在新窗口中打开)。此外,开发人员可以在三种推理方式之间进行选择(在新窗口中打开)选项(低、中、高)可针对其特定用例进行优化。这种灵活性使 o3-mini 在应对复杂挑战时能够“更加认真地思考”,或者在担心延迟时优先考虑速度。o3-mini 不支持视觉功能,因此开发人员应继续使用 OpenAI o1 进行视觉推理任务。o3-mini 从今天开始在 Chat Completions API、Assistants API 和 Batch API 中推出,以选择API 使用层 3-5中的开发人员(在新窗口中打开)。
ChatGPT Plus、Team 和 Pro 用户从今天开始可以访问 OpenAI o3-mini,企业版将于 2 月推出。o3-mini 将在模型选择器中取代 OpenAI o1-mini,提供更高的速率限制和更低的延迟,使其成为编码、STEM 和逻辑问题解决任务的有力选择。作为此次升级的一部分,我们将 Plus 和 Team 用户的速率限制从 o1-mini 每天 50 条消息增加到 o3-mini 每天 150 条消息。此外,o3-mini 现在可与搜索配合使用,以查找带有相关网络资源链接的最新答案。这是我们致力于将搜索集成到我们的推理模型中的早期原型。
从今天开始,免费计划用户还可以通过在消息编写器中选择“推理”或重新生成响应来试用 OpenAI o3-mini。这标志着 ChatGPT 首次向免费用户提供推理模型。
OpenAI o1 仍然是我们更广泛的常识推理模型,而 OpenAI o3-mini 则为需要精度和速度的技术领域提供了专门的替代方案。在 ChatGPT 中,o3-mini 使用中等推理工作量来在速度和准确性之间取得平衡。所有付费用户还可以选择o3-mini-high在模型选择器中选择更高智能的版本,该版本需要更长的时间来生成响应。专业用户可以无限制地访问o3-mini和o3-mini-high。
快速、强大且针对 STEM 推理进行了优化
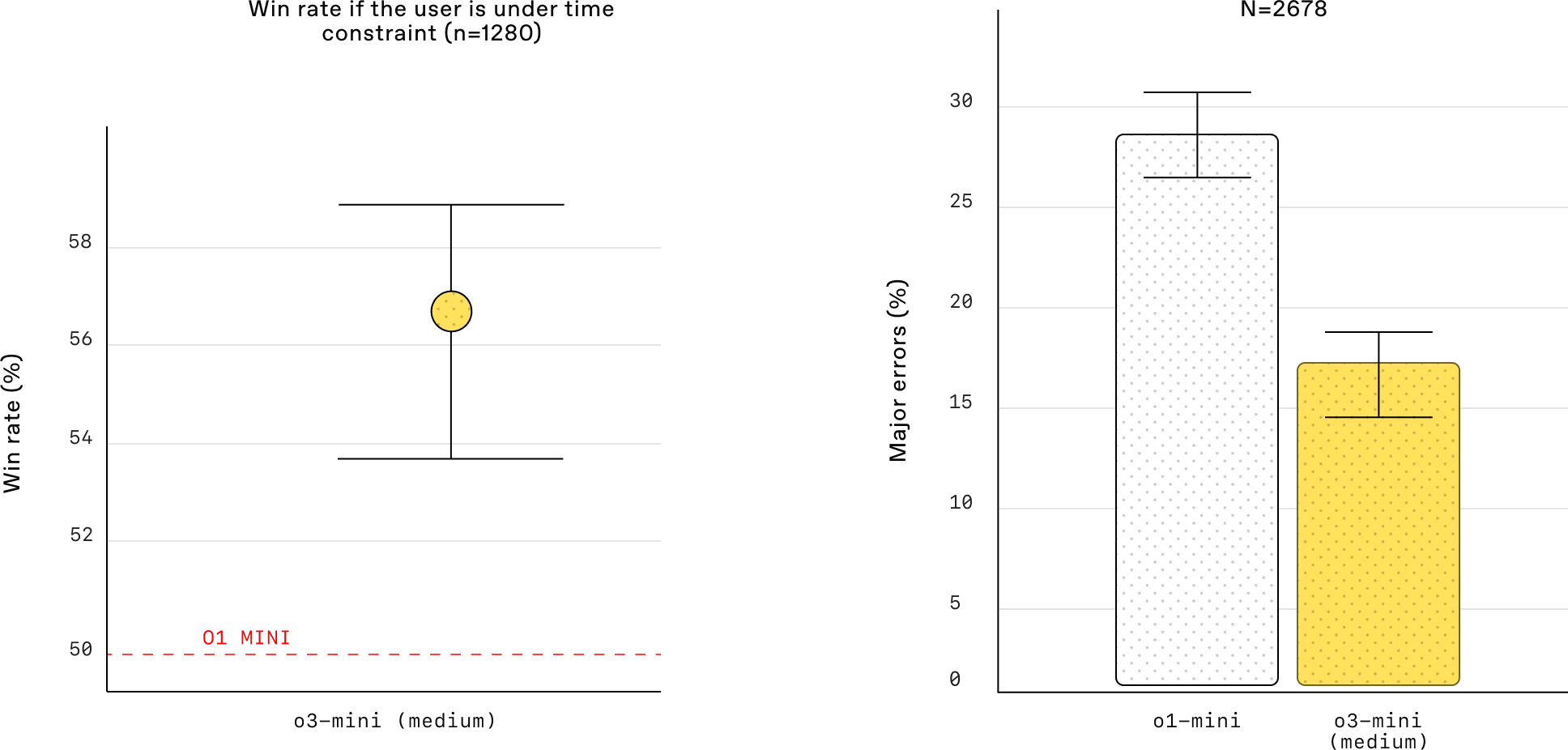
与前身 OpenAI o1 类似,OpenAI o3-mini 已针对 STEM 推理进行了优化。o3-mini 的中等推理努力与 o1 在数学、编码和科学方面的表现相当,同时响应速度更快。专家测试人员的评估表明,与 OpenAI o1-mini 相比,o3-mini 的答案更准确、更清晰,推理能力更强。测试人员在 56% 的时间里更喜欢 o3-mini 的回答,并观察到在困难的现实问题上重大错误减少了 39%。在中等推理努力下,o3-mini 在一些最具挑战性的推理和智力评估(包括 AIME 和 GPQA)上的表现与 o1 相当。
竞赛数学(AIME 2024)
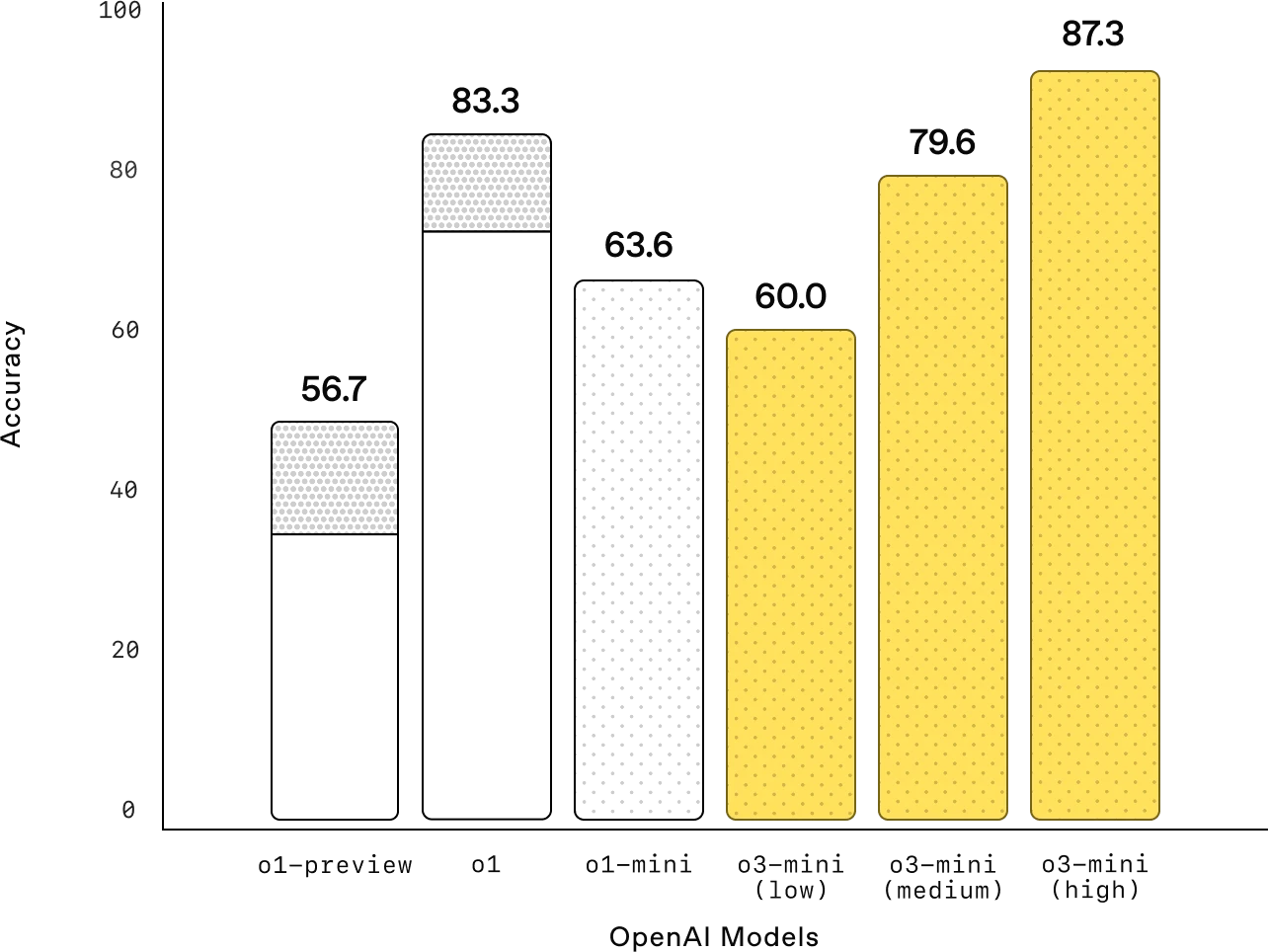
数学:在较低的推理努力下,OpenAI o3-mini 实现了与 OpenAI o1-mini 相当的性能,而在中等努力下,o3-mini 实现了与 o1 相当的性能。同时,在较高的推理努力下,o3-mini 的表现优于 OpenAI o1-mini 和 OpenAI o1,其中灰色阴影区域显示了 64 个样本的多数投票(共识)性能。显示更多
博士级科学问题(GPQA Diamond)
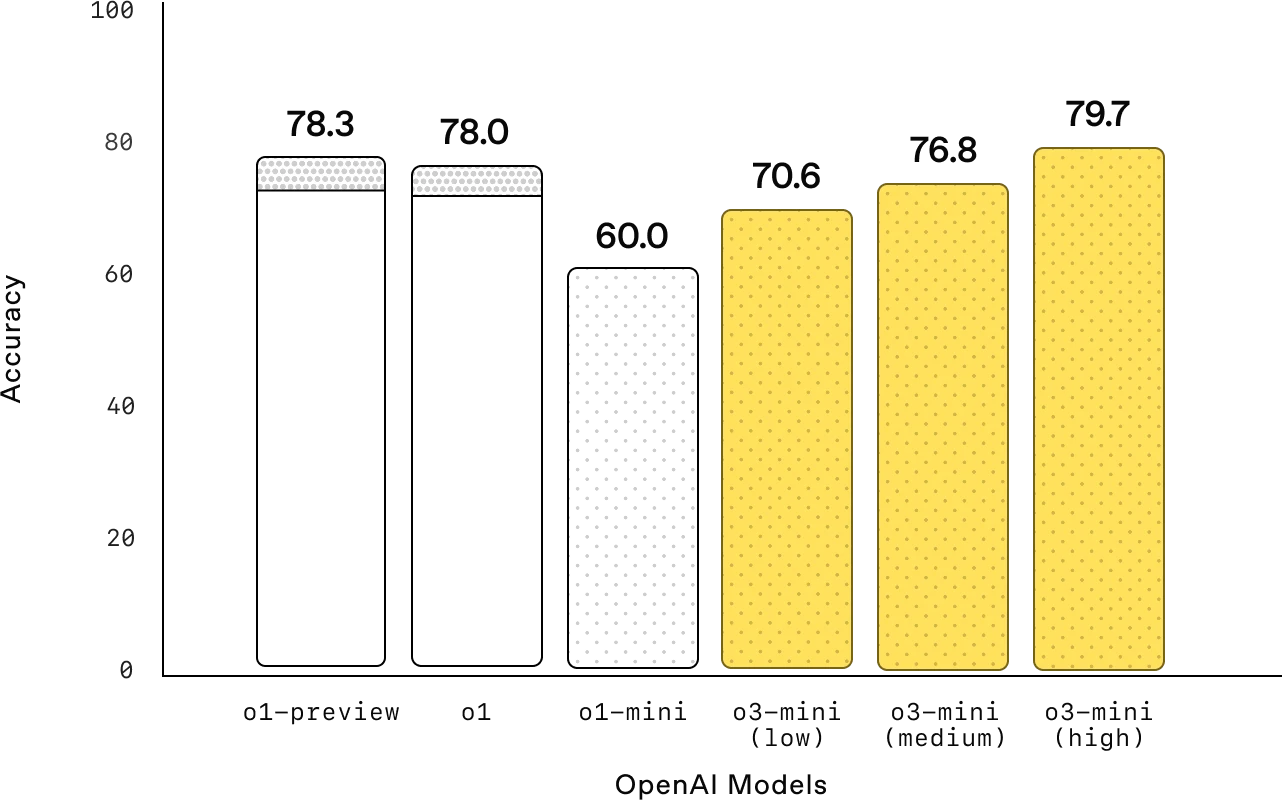
博士级科学:在博士级生物学、化学和物理学问题上,OpenAI o3-mini 在推理工作量较少的情况下,其性能优于 OpenAI o1-mini。在付出较大努力的情况下,o3-mini 的性能可与 o1 相媲美。显示更多
前沿数学

研究级数学:具有高推理能力的 OpenAI o3-mini 在 FrontierMath 上的表现优于其前身。在 FrontierMath 上,当被提示使用 Python 工具时,具有高推理能力的 o3-mini 在第一次尝试时解决了超过 32% 的问题,其中包括超过 28% 的具有挑战性的 (T3) 问题。这些数字是临时的,上图显示了没有工具或计算器时的性能。显示更多
竞赛规则(Codeforces)
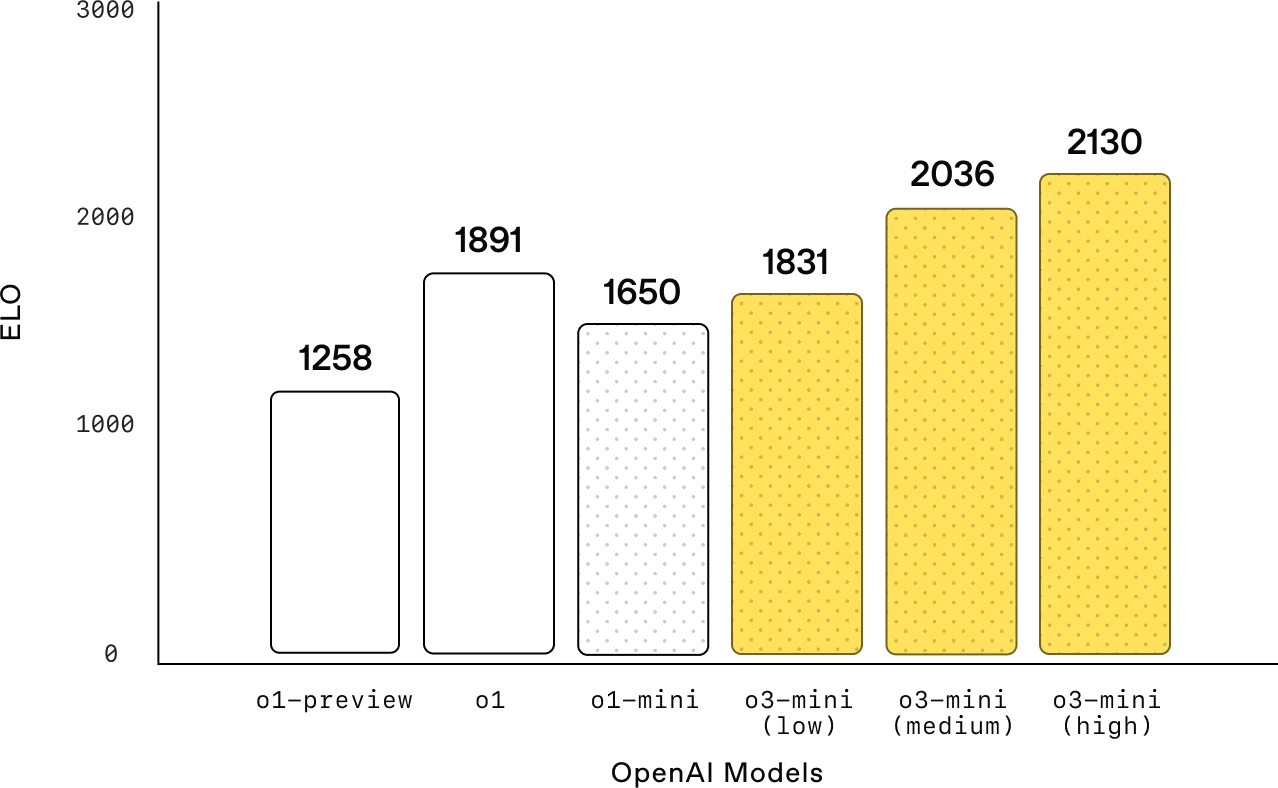
竞赛编程:在 Codeforces 竞赛编程中,OpenAI o3-mini 随着推理努力的增加而获得越来越高的 Elo 分数,均优于 o1-mini。在中等推理努力下,它的表现与 o1 相当。显示更多
软件工程(SWE-bench 验证)
软件工程:o3-mini 是我们在 SWEbench 验证中性能最高的发布模型。有关 SWE-bench 验证结果的更多数据点,包括使用开源 Agentless 脚手架(39%)和内部工具脚手架(61%),请参阅我们的系统卡 。显示更多
LiveBench 编码

LiveBench 编码:OpenAI o3-mini 即使在中等推理工作量下也超越了 o1-high,凸显了其在编码任务中的效率。在高推理工作量下,o3-mini 进一步扩大领先优势,在关键指标上实现了显著增强的性能。
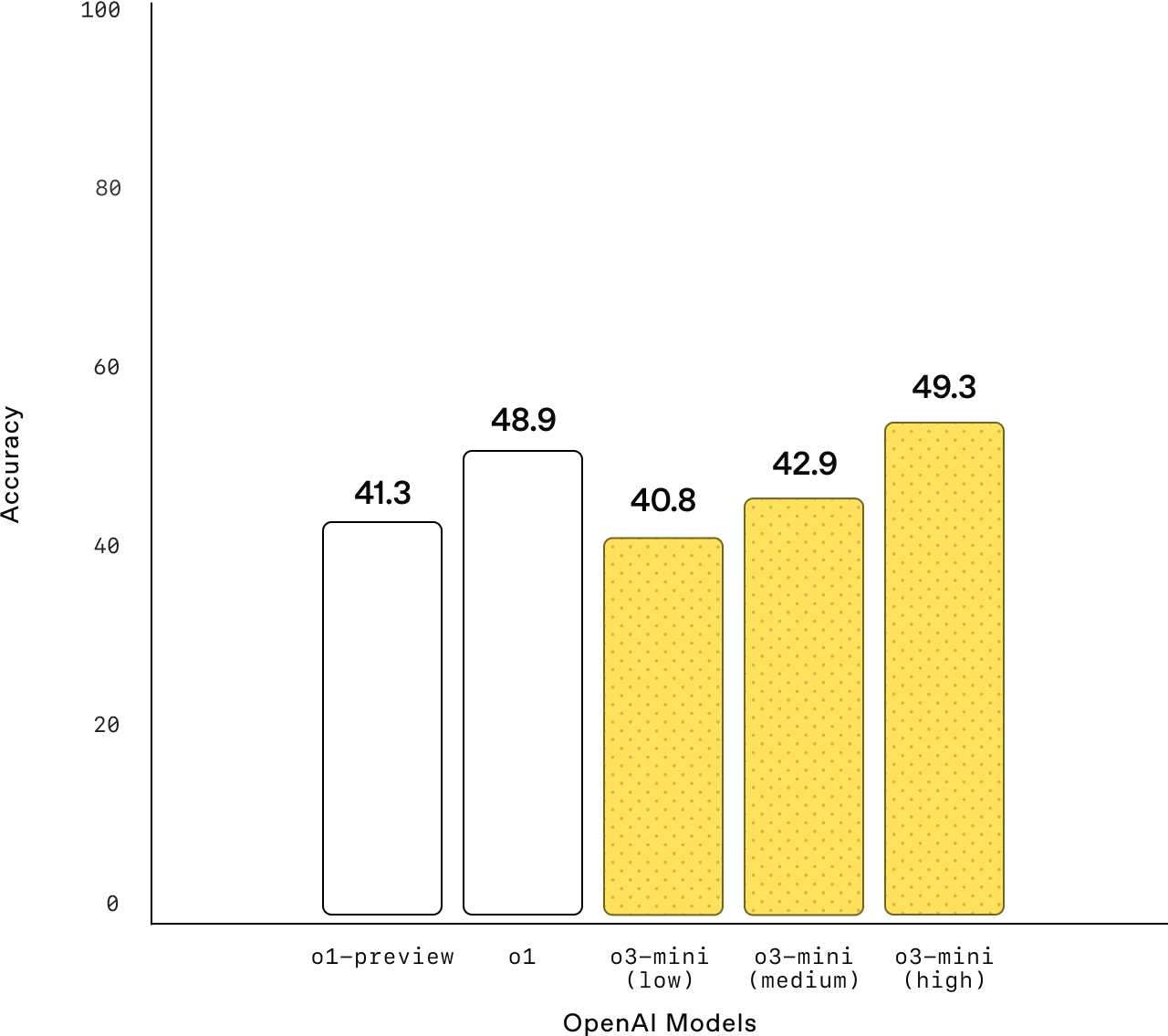
常识
常识:o3-mini 在常识领域的知识评估中表现优于 o1-mini。
人类偏好评估
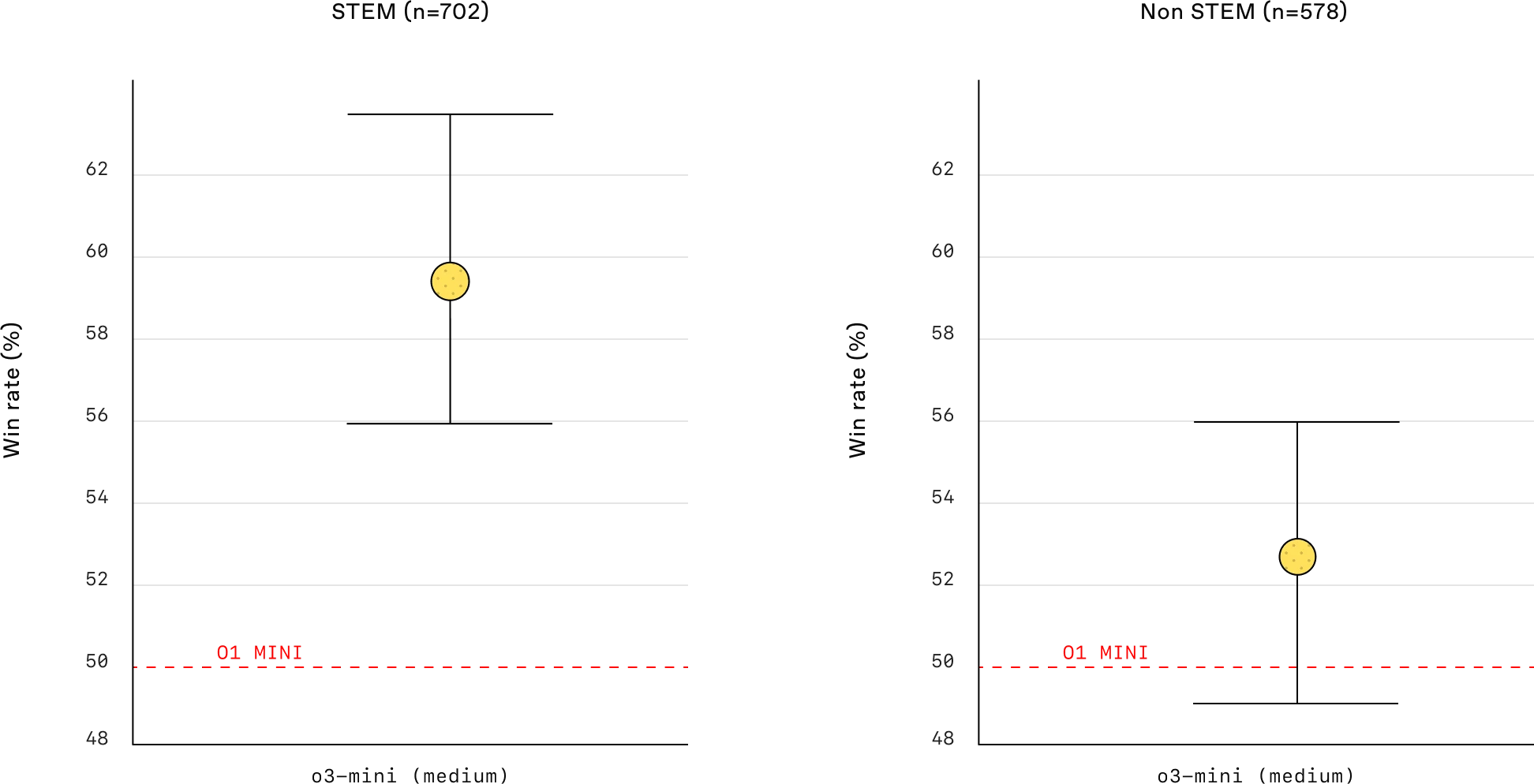
人类偏好评估:外部专家测试人员的评估还表明,OpenAI o3-mini 的答案更准确、更清晰,推理能力比 OpenAI o1-mini 更强,尤其是在 STEM 方面。测试人员在 56% 的时间里更喜欢 o3-mini 的回答,而不是 o1-mini,并且观察到在困难的现实问题上重大错误减少了 39%。显示更多
模型速度和性能
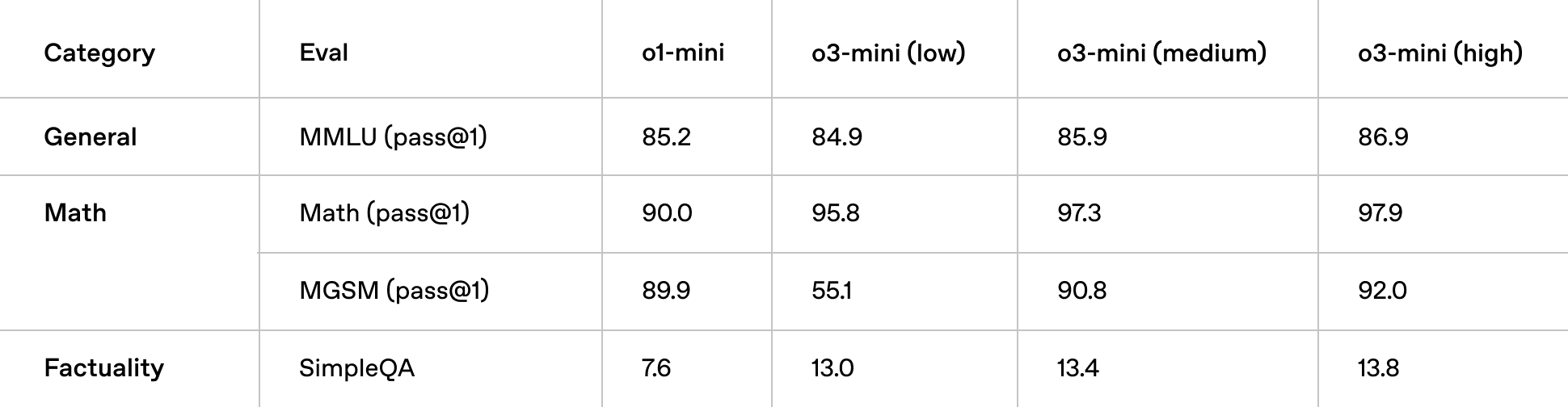
OpenAI o3-mini 的智能可与 OpenAI o1 媲美,性能更快,效率更高。除了上述 STEM 评估之外,o3-mini 还在中等推理工作量的额外数学和事实性评估中表现出色。在 A/B 测试中,o3-mini 的响应速度比 o1-mini 快 24%,平均响应时间为 7.7 秒,而 o1-mini 为 10.16 秒。
o1-mini 与 o3-mini 之间的延迟比较(中等)
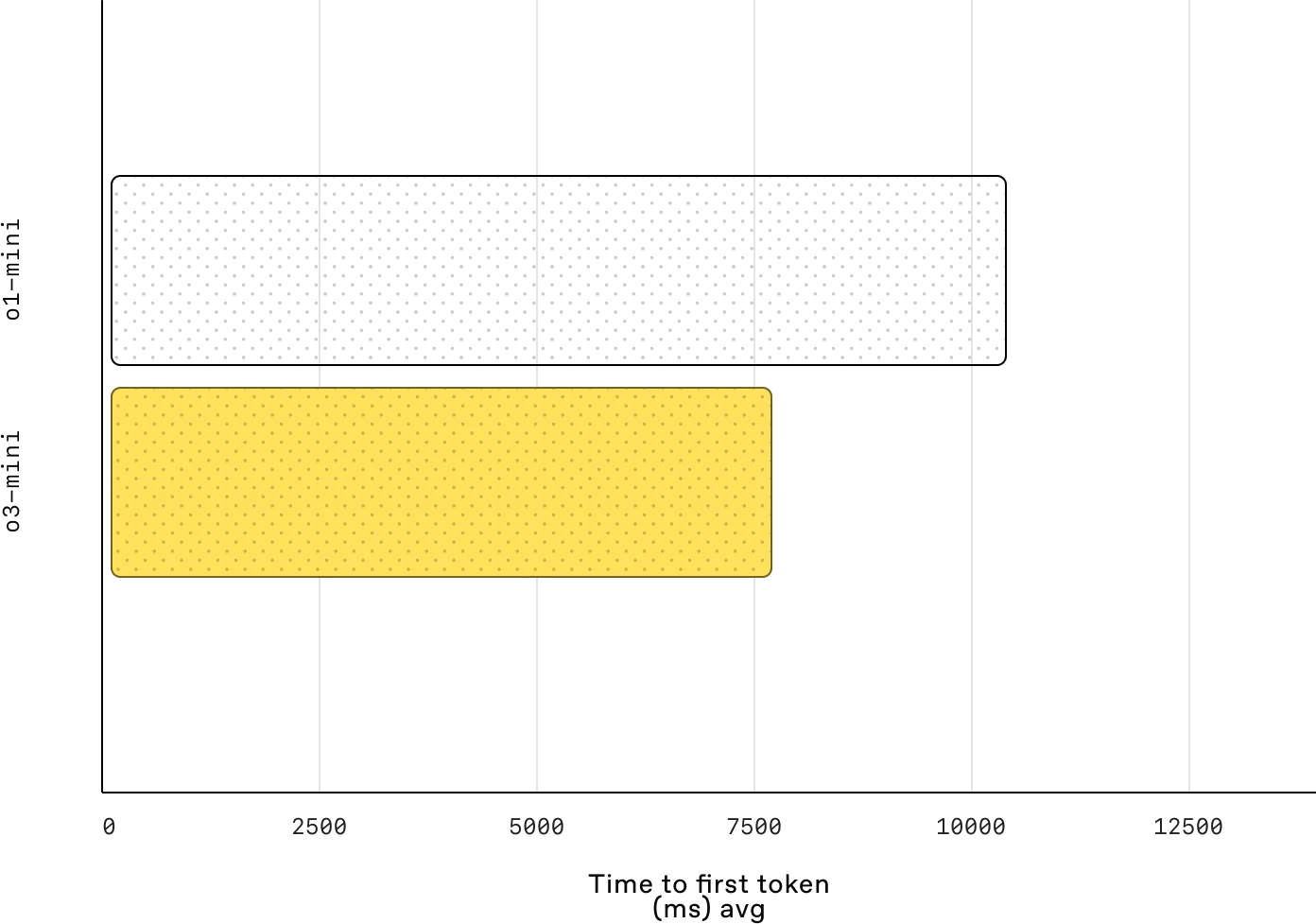
延迟:o3-mini 的第一个令牌平均比 o1-mini 快 2500 毫秒。
安全
我们用来教 OpenAI o3-mini 安全响应的关键技术之一是审慎对齐,即在回答用户提示之前,我们训练模型推理人类编写的安全规范。与 OpenAI o1 类似,我们发现 o3-mini 在具有挑战性的安全性和越狱评估方面明显超越了 GPT-4o。在部署之前,我们仔细评估了 o3-mini 的安全风险,采用了与 o1 相同的准备、外部红队和安全评估方法。我们感谢申请在早期访问中测试 o3-mini 的安全测试人员。以下评估的详细信息以及对潜在风险和我们缓解措施有效性的全面解释可在o3-mini 系统卡中找到。
不允许的内容评估

越狱评估

下一步
OpenAI o3-mini 的发布标志着 OpenAI 向突破高性价比智能界限的使命又迈进了一步。通过优化 STEM 领域的推理并保持低成本,我们让高质量的人工智能更加触手可及。该模型延续了我们降低智能成本的记录——自推出 GPT-4 以来,每个代币的价格降低了 95%——同时保持了顶级的推理能力。随着人工智能的普及,我们仍致力于走在前沿,构建能够平衡智能、效率和安全性的大规模模型。
© Copyright notes
If there is no special statement, the copyright of all articles on this site belongs to AIToolGrid. Without permission, any individual, media, website, or organization may not reproduce, plagiarize, or otherwise copy and publish the content of this site. Otherwise, AIToolGrid reserves the right to pursue related legal responsibilities.
Related posts



No comments...